Hadoop 基础知识
Hadoop

数据处理分为两个阶段:Map和Reduce
Map阶段会对数据进行清洗,过滤以及解析。
然后经过mapreduce进行加工,再传给reduce function
最后得到结果
MapReduce Job
一个Job 包含输入数据,配置,以及MapReduce Program
Hadoop负责把job拆分成一系列Tasks,这些task只有两种类型:Map和Reduce
这些task被YARN调度,在节点上运行。如果Task失败了,它会自动被安排在另一个节点上运行。
(注:这个Yarn和nodejs的yarn容易发生命令行冲突,因此也可以用yarnpkg来调用)
Splits
Hadoop会把数据纵向拆开,分给不同的task去做map,这样可以提升效率。
对大多数Job来说,Split size就是HDFS Block的大小,128MB
如果大于128MB,就有可能会出现结果存在多个Block中,可能会存在多个节点里,出现网络请求。
Map Task的结果是写在本地磁盘,不是写在HDFS里的,因为它属于中间结果
Data Flow
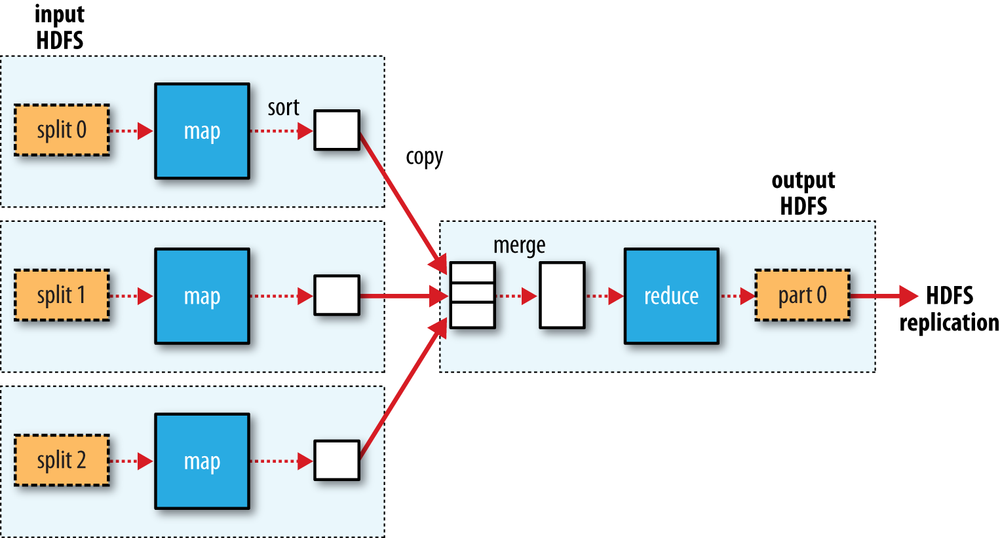
虚线代表本地数据流,实线代表跨Node数据流。
Multiple Tasks(shuffle)
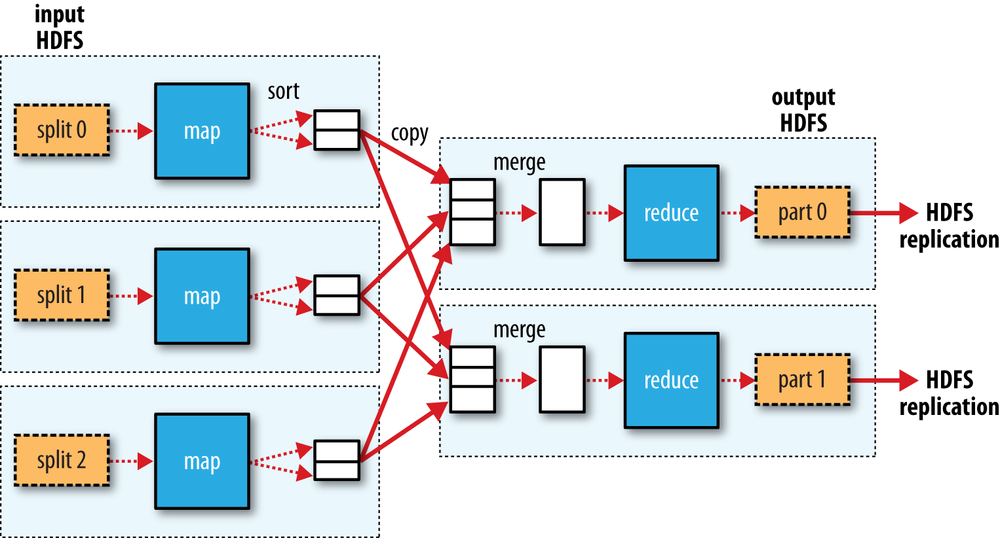
Combiner function
除了Mapper和Reducer,还可以根据实际情况选择Combiner 来减少数据的交换。
比如求最大值,就可以用Combiner,在每个Map结束后直接调用,最后的结果不变,但参与网络交换的数据大大减少了。
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
当然,不是所有问题都能够用得到。
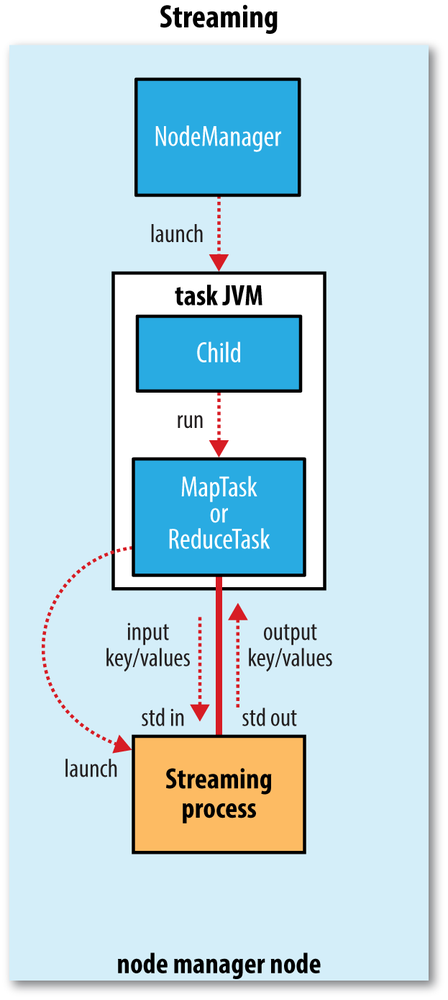
Hadoop Streaming
理论上,只要是能够读取/写入 Unix标准IO的都能够使用Hadoop Streaming,所以不一定要用Java。
Hadoop Distributed Filesystem (HDFS)
Hadoop其实也可以和其他文件系统结合,比如Amazon S3或者本地文件系统。
HDFS的特点:
支持超大文件、民用硬件、流式文件存取
HDFS的缺点:
延迟(挖坑 HBase)、大量小文件
Append-only,不支持随机写入,不支持Multi writer
Blocks
HDFS的文件都被Chunk成Block进行存储,每个Block 128MB。当然,不像磁盘的4K 块大小,小于128M的文件在HDFS里并不会占有128MB,而是文件原来的大小。
之所以HDFS的块那么大,就是为了最小化seek time,也就是寻找块的时间。
Namenodes and Datanodes
Namenode: master
负责管理文件系统的namespace,filesystem tree,metadata,directories。
存储在本地,namespace image和edit log
并且,在系统启动时,还会通过datanode建立一个文件块和datanode的位置映射,但是是非持久化的。
Namenode如果挂了,数据就全丢失了。因为没有办法知道如何从块重建文件。
第一种办法,就是备份Namenode的state,写到本地磁盘或者nfs。
第二种办法,就是另外运行一个node来定时merge namespace image和edit log。
Datanode: workers
存取块,接受namenode或者client的请求。
Block Caching
指定一些经常使用的Block,放入内存中作为Cache
Memory
1,000 MB per million blocks of storage
a 200-node cluster with 24 TB of disk space per node, a block size of 128 MB, and a replication factor of 3
>>> 200* 24000000 / 128 / 3 / 1000000 * 1000
12500.0
Federation
HDFS Federation, 2.x版本开始, 多个Namenode分别管理集群中的一部分
比如Node 0管理/user,Node 1 管理/share
HDFS HA
NFS或者QJM,来让一对热备的Namenode能够同时访问到edit log,然后能够接管
QJM就是一个小型的HDFS,提供高可用edit log
Failover
ZooKeeper确定只有一个Namenode是活动的
Fencing
假设原有的Node依然在运行,但由于网络原因被认为失效了,触发了Failover,需要一些机制来确保这个Node不造成太多的伤害。这个过程被称为Fencing
QJM只允许同时有一个Namenode写edit log,但是NFS没办法做到
STONITH, or “shoot the other node in the head,”
直接控制电源让另一个host关机
简单命令
From Local
hadoop fs -copyFromLocal input/docs/quangle.txt /user/tom/quangle.txt
To Local
hadoop fs -copyToLocal quangle.txt quangle.copy.txt
Data Flow
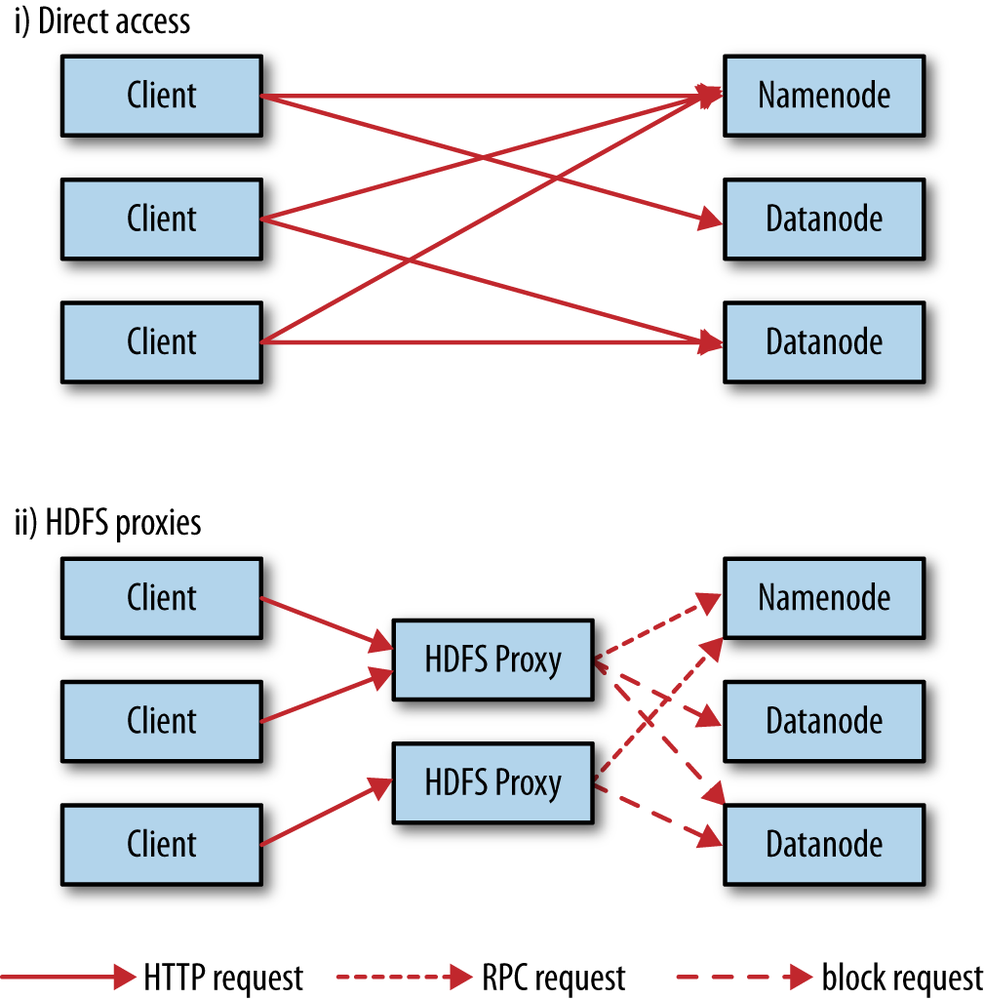
Client Access Mode
File Write
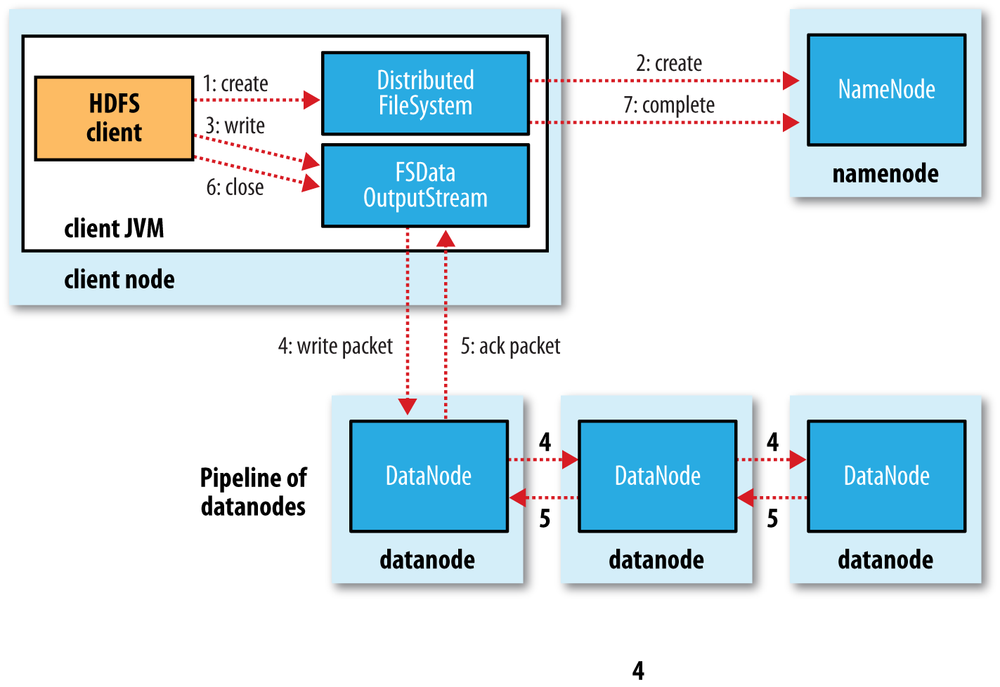
NameNode会先去check 文件是否存在,是否有权限等。如果check通过了,会增加一条new file的record。
dfs.namenode.replication.min replicas (which defaults to 1) are written, 就会success
asynchronously replicated across the cluster, dfs.replication, which defaults to 3
File Read
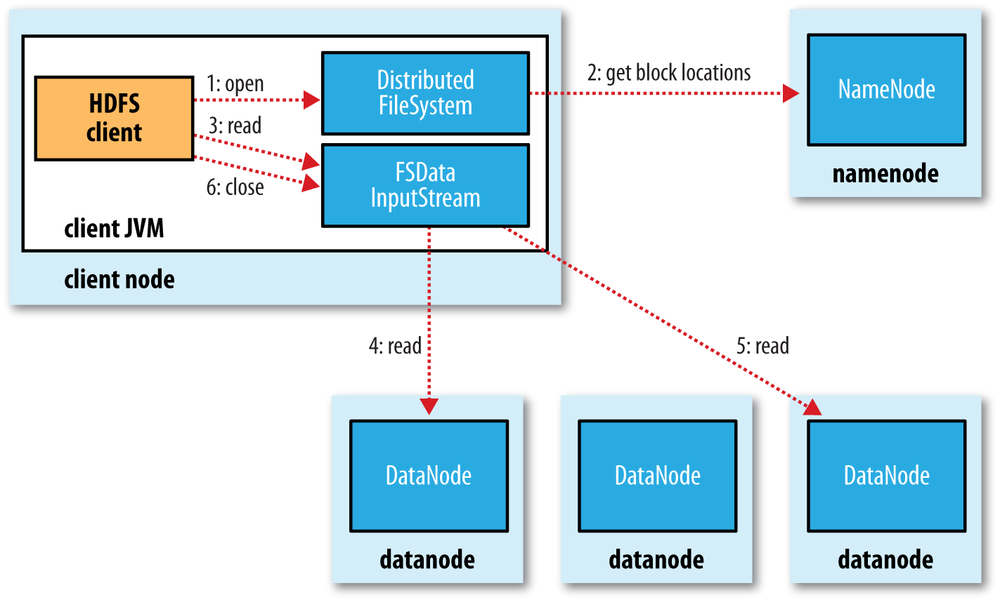
Distances
- distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)
- distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
- distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)
- distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)
Replica Strategy
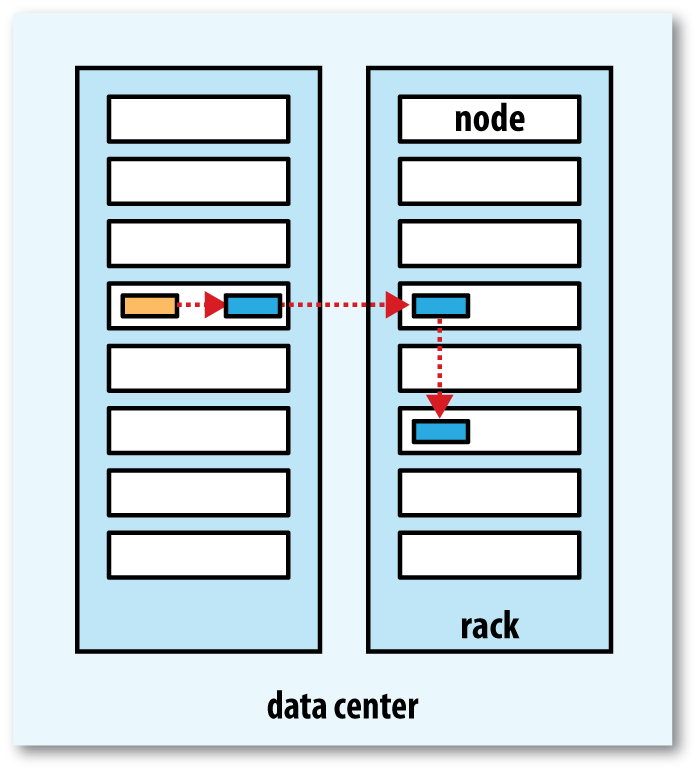
同Node,Node On other rack, other node on that rack
Flush
正在写的Block,很可能还是读取不了的状态,需要达到一个Block的大小后缓存才会被Flush。当然也有API可以Force Flush
Parallel Copying
hadoop distcp file1 file2
distcp本身是一个MapReduce Job,每个file都被一个map copy。
YARN (Yet Another Resource Negotiator)
Yarn 是Hadoop的集群资源管理系统。
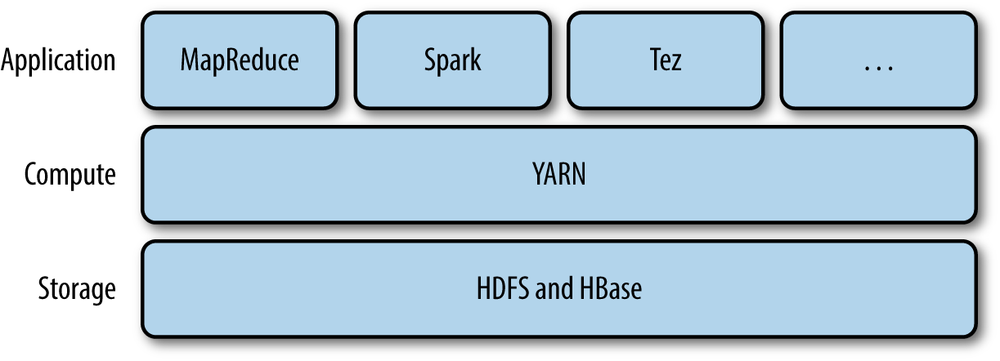
提供一个API来访问集群的资源,通常是被更高级的API调用的。
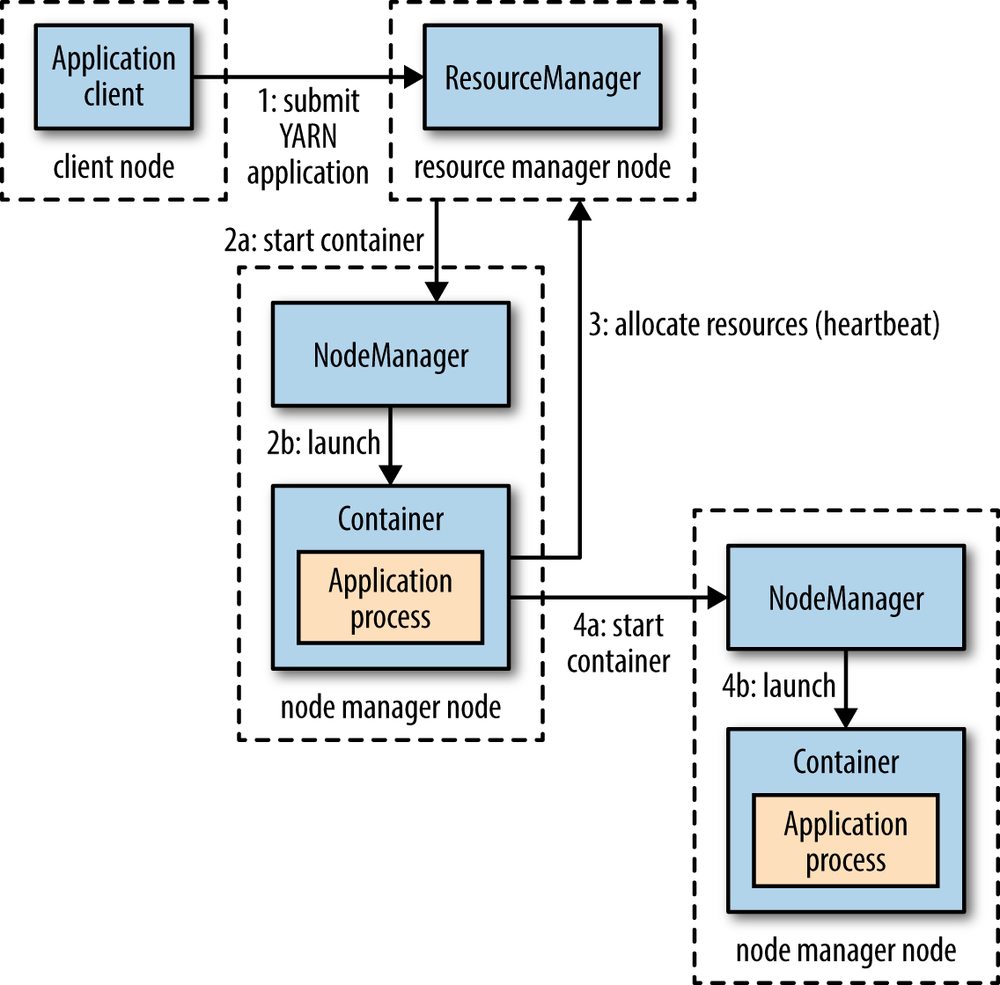
这个Container可以是Unix Process,也可以是Linux的cgroup
Resource Requests
Yarn Application可以在运行前就申请好所有资源,或者在运行时动态地申请更多的资源。
Spark就是使用的前一种方式
Application Lifespan
App per job
App per workflow/session of jobs
Long-running
Spark采用的第二种
Mapreduce 1 and Yarn
| MapReduce 1 | YARN |
|---|---|
| Jobtracker | Resource manager, application master, timeline server |
| Tasktracker | Node manager |
| Slot | Container |
| 4000 nodes and 40000 tasks | 10000 nodes and 100000 tasks |
Scheduler Options
FIFO、Capacity、Fair
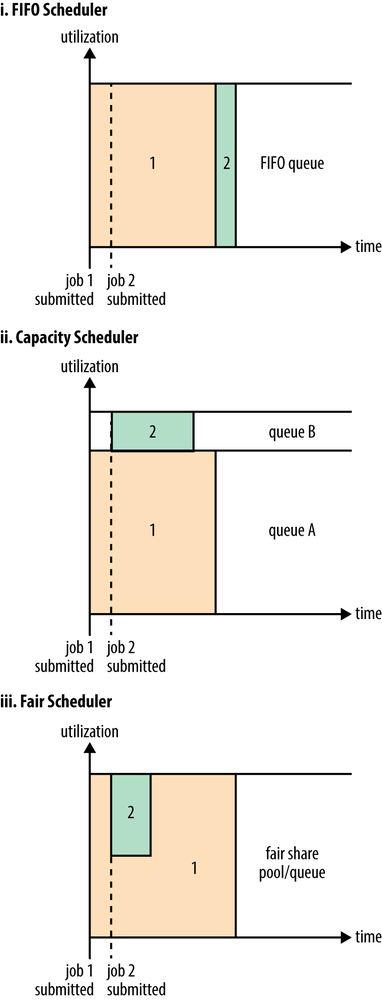
Capacity scheduler的资源是在配置里定义的
Fair Scheduler:用户A 和用户B 如下图
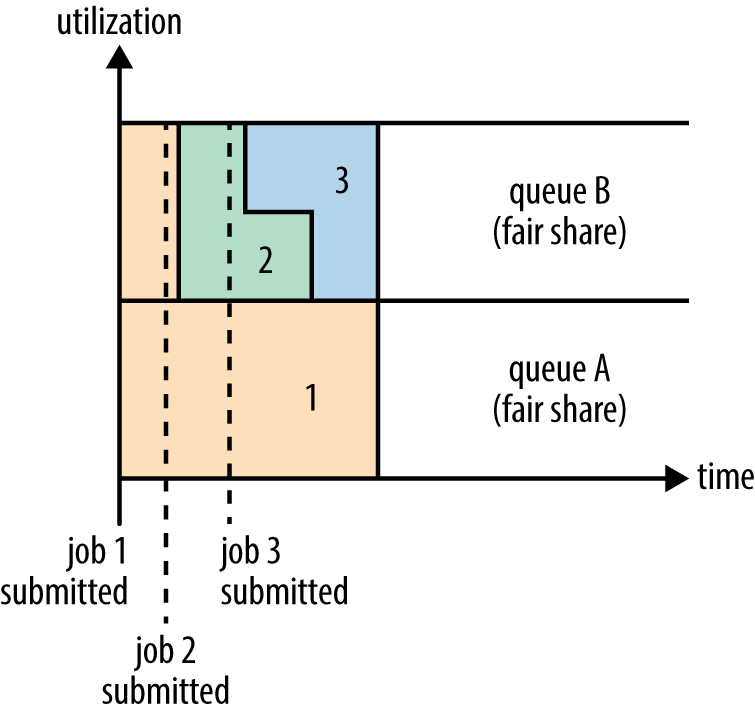
资源在用户之间也是Fair shared。
Dominant Resource Fairness
这个很有意思,是针对任务使用异构资源的算法。
假如集群有100CPU 10T 内存,A任务需求 2CPU 300G内存,B任务需求6CPU 100G内存
它是按照资源需求占集群总资源的百分比算的,A占2% 3%,B占6% 1%
所以B的Container数量会比A少一半,来达到平衡
默认DRF是关闭的。
Data Integrity
HDFS默认会在数据写入后计算checksum,然后在读取时验证。
默认每512byte就进行一次CRC-32C checksum,存一个4byte的哈希值。
Datanode 负责在数据写入之前验证checksum,然后在读取时也是一样。每个Datanode都有一个persistent log来记录verification,记录最后一次每个Block验证的时间。Client验证Block后,会回传结果给Datanode更新log。
除了在读写操作以外,DataBlockScanner还会在后台定期检查验证blocks。
当发现出错后,由于HDFS有多个备份,就可以把一个好的备份复制过来。
Compression
| Compression format | Tool | Algorithm | Filename extension | Splittable? |
|---|---|---|---|---|
| DEFLATE[a] | N/A | DEFLATE | .deflate | No |
| gzip | gzip | DEFLATE | .gz | No |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | No[b] |
| LZ4 | N/A | LZ4 | .lz4 | No |
| Snappy | N/A | Snappy | .snappy | No |
Splitting
如果压缩文件大于128MB,那么就会被分成多个Block。然而,不是所有格式都支持任意区域开始解压缩。比如gzip,就必须同一个Map完成连续多个Block的读取来完成解压。
Bz2,LZO都是可以分块的,这样可以分布式地处理
SequenceFile
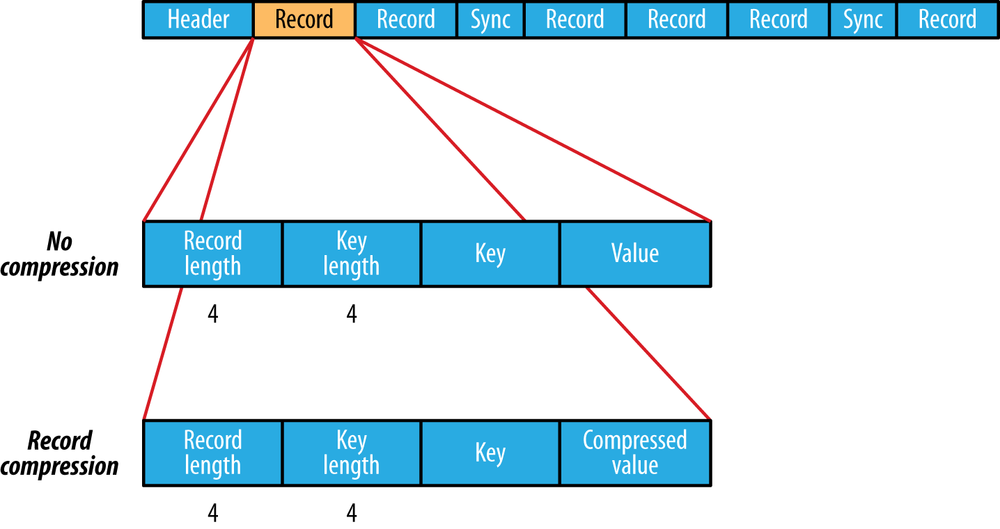
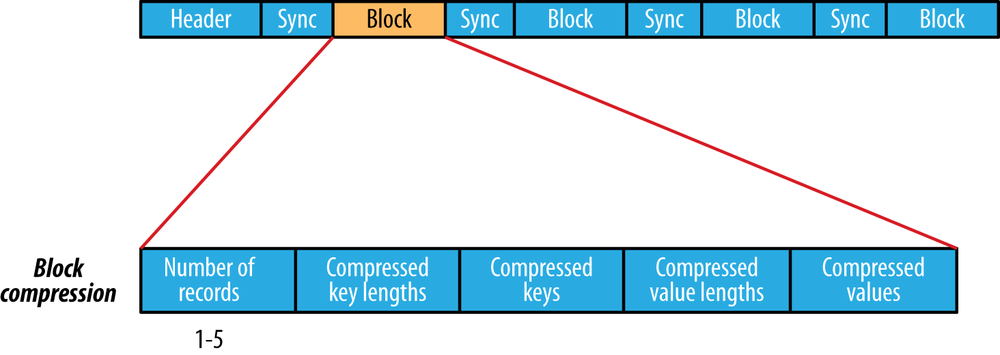
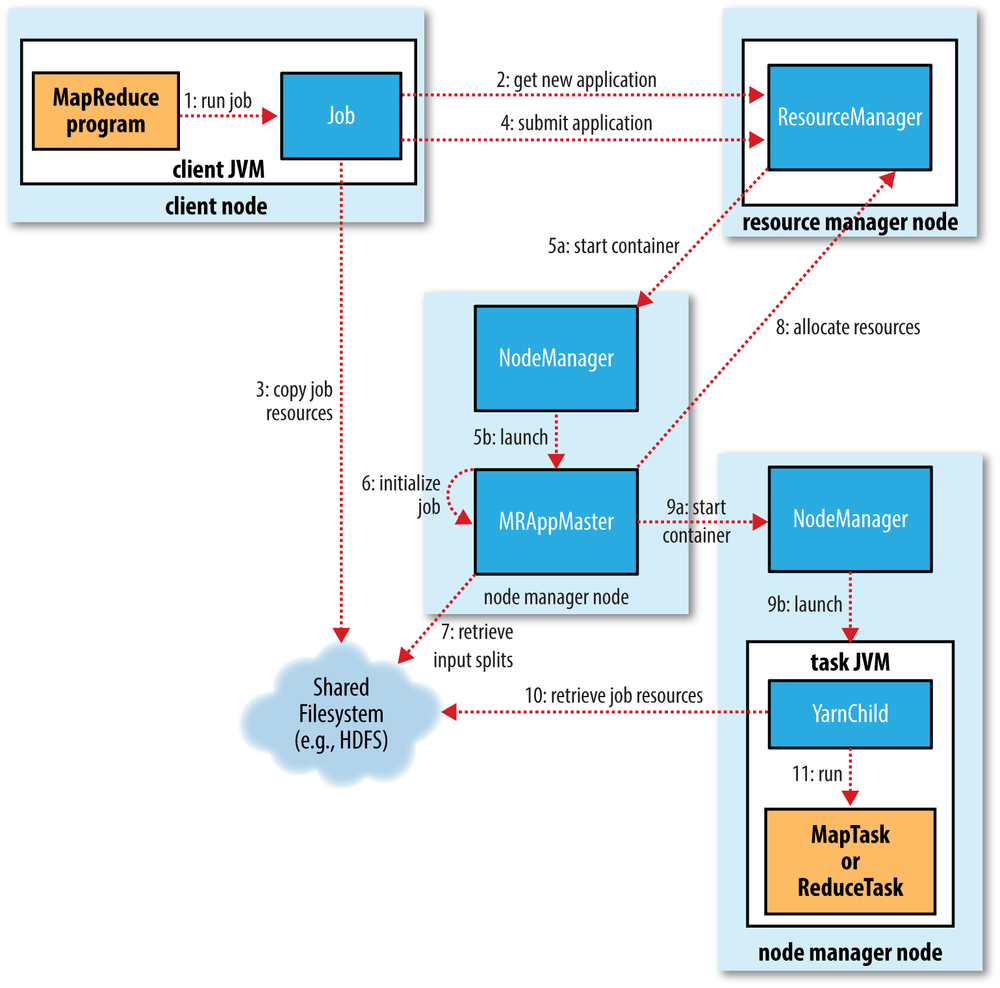
Run a MapReduce Job
Streaming
Shuffle and Sort
Map Side
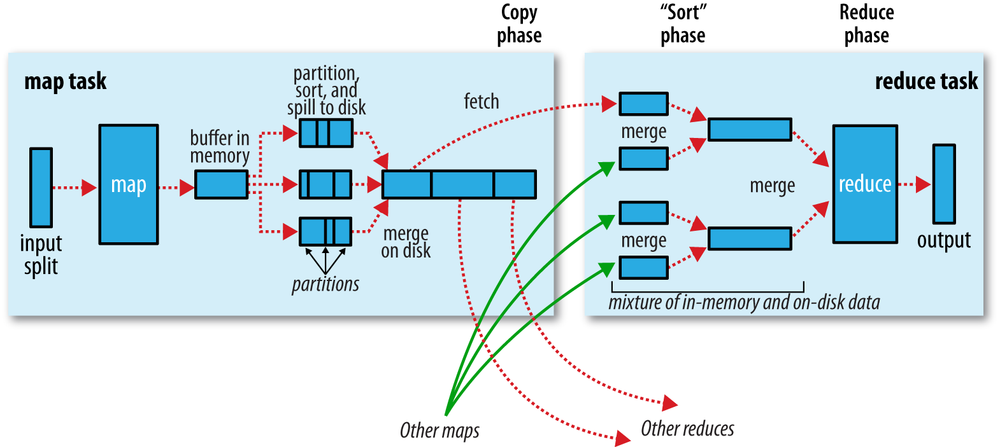
每个Map都有一个memory buffer,默认是100MB。
Map会将输出写到这个buffer里,每当buffer写满后,就会触发spill,创建一个磁盘上的spill文件然后清空buffer。这个buffer是分区(partitioned)的,对应下游的reducer。然后对每个partition,后台会有一个进程对其中的key进行sort,然后再对sort运行一边combiner。
多个Spill文件会被合成为一个分块的有序文件。如果合成前spill 文件大于3个,combiner会再次运行,否则不会运行。在此过程中,数据也会被压缩。
Reduce Side
当Map 任务完成后,会向Application Master发送消息,然后就知道了Map output和host的关系。只有当Application Master向map host发送消息要求删除结果后,结果才会被删除。
Copy phase:从map output复制结果,后台有多个copier threads,默认是5个。
当copies被复制到磁盘上,就会开始merge。这个过程由merge factor控制,如果默认值10,收到了50个结果,就要merge 5次后形成5个文件。最后这5个文件不会被merge,而是直接送到reducer
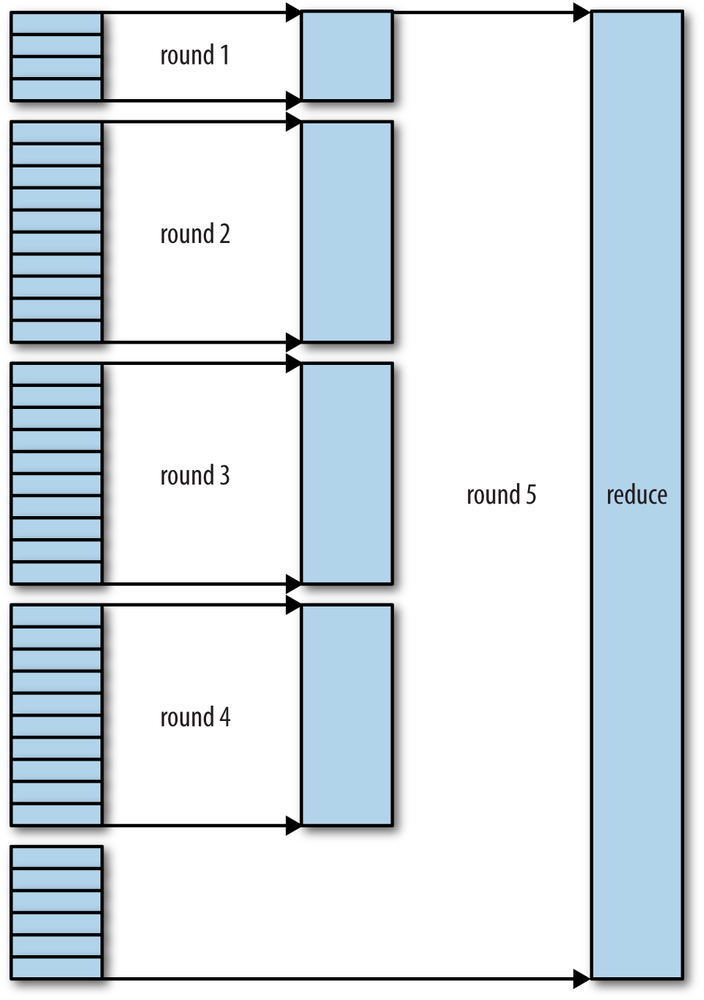
如果是40个文件:第一次4个,然后10、10、10 这四次产生的4个文件和最后剩下的6个合并成为一次merge。
这样做是为了最小化io次数。
Speculative Execution
如果hadoop在运行过程中发现哪个task比预期执行地慢,就会启动一个同样内容的backup 任务。谁先完成,另一个都会被kill掉。这部分只会占很小一部分,显著慢于其他任务时才会触发。
Filesystem Image and Edit log
当客户端发起写请求,这个操作会被记录在edit log中。namenode在内存中也会有一个metadata的数据结构,在edit log修改后更新。这个内存中的metadata会用来响应读请求。
Edit log事实上是很多文件,如edits_inprogress_0000000000000000020 后缀是transaction ID,前缀是edit。
每次只有一个文件打开可以写入,在事务完成后flush,sync。
fsimage是 metadata的完全checkpoint,通常很大,GB级别。内容包含文件系统中所有文件夹和文件的inode,代表metadata。fsimage不包含block在哪个datanode上存储。
为了不让Edit log过多,只能另起一个namenode,定时地取最新的fsimage和edit log,然后合并成最新的fsimage回传给namenode,这样edit log就不会太多。
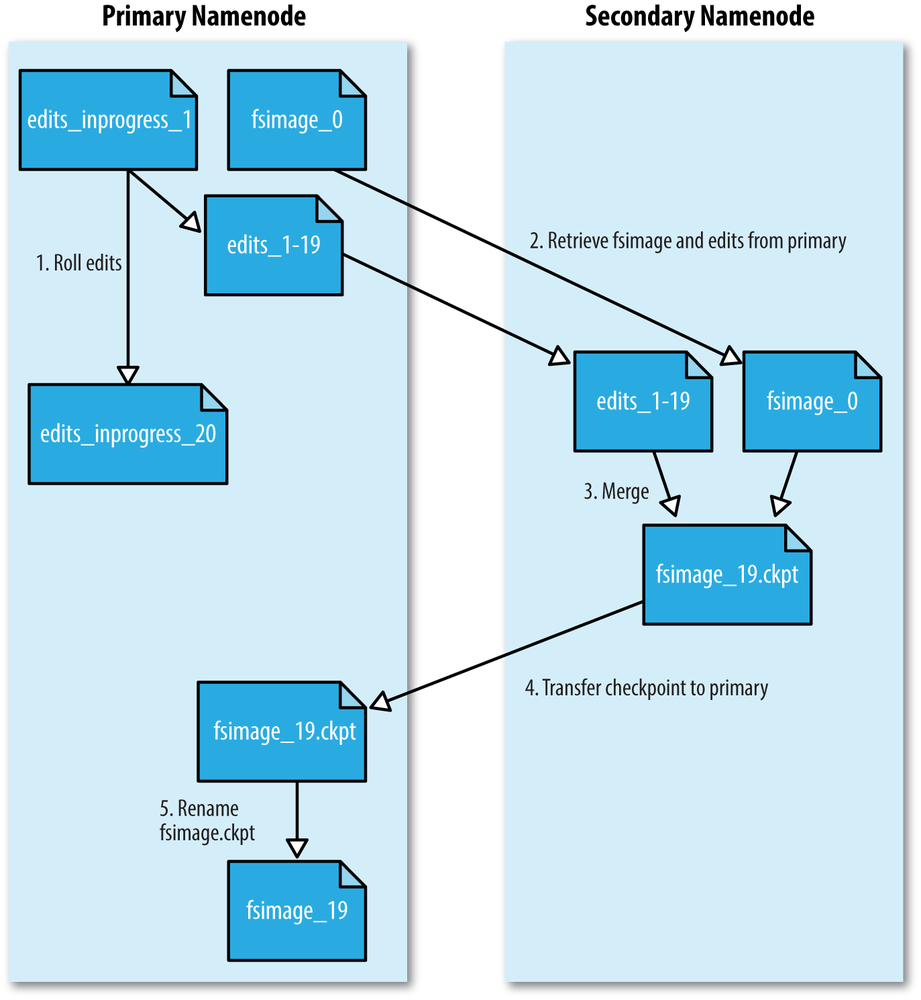
Safe mode
只对client提供文件系统的Read-only view
Balancer
把空间使用率最高的node上一部分block移动到最低的node
start-balancer.sh
安装
brew install hadoop
注意安装的位置
本书的代码可以在github上找到,repo owner就是书的作者
hadoop-book git:(master) ✗ hadoop jar /opt/homebrew/Cellar/hadoop/3.3.3/libexec/share/hadoop/tools/lib/hadoop-streaming-*.jar \
-input input/ncdc/sample.txt \
-output output \
-mapper ch02-mr-intro/src/main/python/max_temperature_map.py \
-reducer ch02-mr-intro/src/main/python/max_temperature_reduce.py
$ open core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
$ open hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
$ open mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name> <value>/opt/homebrew/Cellar/hadoop/3.3.3/libexec/share/hadoop/mapreduce/*:/opt/homebrew/Cellar/hadoop/3.3.3/libexec/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
open yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
Ssh 本地可以跑通,在设置里打开权限
相关项目(深坑)
Avro
数据序列化系统
Parquet
列存储格式
Flume
数据Ingestion
Sqoop
从关系型数据库提取数据
Pig
处理大型数据集
Hive
Data warehouse
Crunch
Map Reduce高级API
Spark
大数据处理引擎
HBase
Big table
这些有空再更新吧……